LakeSoul 总体概念介绍
LakeSoul 是一个端到端的实时湖仓存储框架,使用开放式的架构设计,通过 NativeIO 层,实现高性能的读写(Upsert 和 Merge on Read),统一支持多种计算引擎,包括批处理(Spark)、流处理(Flink)、MPP(Presto)、AI(PyTorch、Pandas、Ray),能够部署在 Hadoop 集群、Kubernetes 集群。LakeSoul 的整体架构如下图所示:
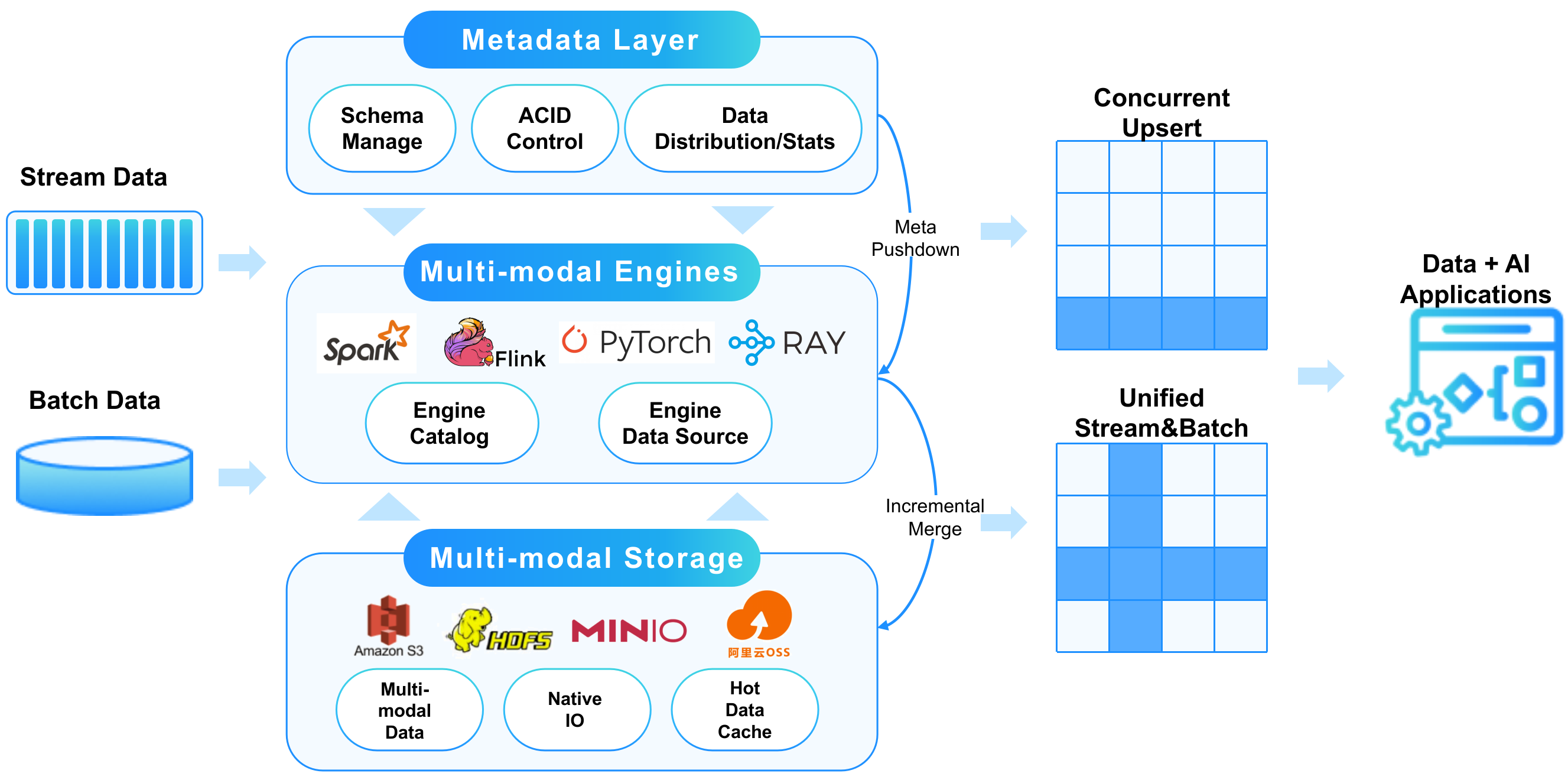
LakeSoul 的架构
元数据管理层。通过 PostgreSQL 实现中心化的元数据管理、写并发原子性和一致性控制、读版本隔离(MVCC)等。通过 PostgreSQL 强大的事务能力,实现了自动的并发写冲突解决(Write conflict reconsiliation)、端到端的严格一次(Exactly Once)保证。通过 PostgreSQL 的 Trigger-Notify 事件监听机制,实现自动分离式弹性 Compaction、过期数据清理等功能,从而实现“自治式”的管理能力。
此外,中心化的元数据管理还能够很容易地实现多套存储在一个湖仓实例中统一管理,例如多个S3桶、多个 HDFS 集群上的数据,都能够在一个湖仓元数据中管理。
NativeIO 层。使用 Rust 实现的向量化 Parquet 文件读写。对于实时更新的场景,使用了“单层”类 LSM-Tree 的方式,将主键表根据主键哈希分片后排序写入,读时进行自动合并,从而实现了 Upsert 功能。NativeIO 层针对对象存储和 MOR 场景,做了大量性能优化,大幅提升了湖仓的 IO 性能。NativeIO 层也实现了列裁剪、Filter 下推等功能。
NativeIO 层使用 Rust 实现的原生 IO 库,并统一封装了 Java、Python 接口,使得 LakeSoul 能够很方便地与各类大数据、AI 框架实现原生对接,省去文件格式或者内存中的转换开销,提升执行效率。
NativeIO 层支持 HDFS、S3、OSS、OBS、MinIO 等常见的存储服务。
引擎对接层。实现 Spark、Flink、Presto、PyTorch、Pandas、Ray 等框架的 Catalog 和 DataSource,我们也在不断持续集成。在多种引擎之间,尤其是大数据处理和 AI 计算之间能够无缝衔接。因此 LakeSoul 很适合作为 Data+AI 一体化架构的湖仓数据底座。
LakeSoul 的核心功能
LakeSoul 的目标是构建一套端到端的湖仓平台,涵盖数据集成、实时/批量数据 ETL 计算和 AI 计算。主要核心功能点包括:
- 实时数据集成。LakeSoul 基于 Flink CDC 实现了整库同步的功能,目前已支持 MySQL、PostgreSQL、PolarDB、Oracle 等数据库。对于所有数据源,均支持整库同步、自动新表发现同步、自动 Schema 变更同步(支持加列、减列)。
- 流批计算。LakeSoul 支持 Spark、Flink 等框架进行流、批 ETL 计算。其中主键表在 Flink 中支持 ChangeLog (CDC)读取,从而实现流式增量计算。
- 数据分析查询。LakeSoul 通过高性能的 IO 层实现提升数据分析查询的性能。同时也能够支持各类向量化的计算引擎。当前 LakeSoul 已经实现了 Spark Gluten Engine 的对接,在 Spark 上实现原生向量化计算。LakeSoul 也在进一步实现与 Apache Doris、Clickhouse、Presto Velox 等高性能向量化查询引擎的对接。
- AI 计算。LakeSoul 能够支持 PyTorch、Ray、Pandas 等各类 AI 和数据科学框架分布式读取,进行 AI 模型的训练和推理。
- 多租户空间和 RBAC。LakeSoul 内置了多空间隔离和权限控制。可以在湖仓中划分多个工作空间,每个工作空间可以加入多个用户。不同空间的元数据、物理数据实现了访问权限隔离。空间的权限隔离,对于 SQL、Java/Scala、Python 作业,包括提交到集群上执行的作业,均是有效的。
- 自治管理。LakeSoul 提供了自动分离式的弹性 Compaction 服务、自动数据清理服务等,减轻运维工作量。其中分离式弹性 Compaction 服务由元数据层自动感知触发,并行执行,不影响写入任务的效率。
- 快照和回滚。LakeSoul 表可以支持按照时间戳进行快照读和版本回滚。
- 出湖同步。LakeSoul 提供封装好的流式、批式出湖任务。
LakeSoul 的核心概念
在 LakeSoul 中,数据被组织成表。表支持多级 range 分区,支持指定主键。
分区表采用与 Hive 相同的目录组织结构,支持动态分区写入。主键表使用哈希分桶排序的方式存储,主键可以是一个或多个列组成。
在创建表时,可以通过 Spark Dataframe、Spark SQL、Flink SQL 等方式。建表时可以直接使用 partition by 子句指定分区列,使用表属性hashPartitions指定主键列,使用表属性hashBucketNum指定哈希分片个数。
建表时可以使用 Spark、Flink 原生的所有数据类型。数据类型会被翻译成 Apache Arrow 的类型,最终翻译成 Parquet 文件的类型。类型支持多级嵌套(Struct)。
非主键表
非主键表可以支持多级分区,但是没有主键。非主键表只能以 Append 方式追加写入。适合没有明确主键的场景,如日志数据等。非主键表的 Append 写入可以并发执行,即可以有多个批、流作业对表/分区并发写。
在 Spark、Flink 中,可以使用 DataFrame、DataStream API 写入,可以使用 SQL insert into 语句写入非主键表。非主键表在 Spark、Flink 中均可支持流读。在 Presto、AI 框架中支持批读。
主键表
主键表可以指定多级分区,以及一个或多个主键列。主键列不能为空值。相同的主键,在读取时会自动合并取最新的值。
主键表只能够支持 Upsert 方式进行更新。可以使用 Spark API 或者 MERGE INTO SQL 语句进行更新。Flink 中 INSERT INTO SQL 会自动按照 Upsert 方式执行。
主键表可以支持并发写入更新,支持部分列更新(Partial Update)。在并发更新时,需要应用层保证写入顺序不发生冲突。一般情况下,如果有多个流同时更新主键表的不同列,可以采用并发更新的方式进行写入,这样不会发生数据冲突,也能提高并发度。
主键表还能够支持 CDC 格式。对于从数据库同步的表,需要开启 CDC 格式。同时 CDC 格式在 Flink 流读时会自动支持 ChangeLog 语义,从而能够在 Flink 中实现流式增量计算。
主键表在 Presto 和 AI 框架中同样支持批读。
快照读
LakeSoul 在 Spark、Flink 中支持快照读(Time Travel)和版本回滚。参考文档:Spark 快照功能、Flink 快照读。